Research Article: 2022 Vol: 25 Issue: 3S
Public sentiment analysis of the major competitors in the electronics sector in the Indian context
Rinku Sharma Dixit, New Delhi Institute of Management
Shailee Lohmor Choudhary, New Delhi Institute of Management
Sameeksha Jain, New Delhi Institute of Management
Rahul Srivastava, New Delhi Institute of Management
Citation Information: Dixit, R.S., Choudhary, S.L., Jain, S., & Srivastava, R. (2022). Public sentiment analysis of the major competitors in the electronics sector in the Indian context. Journal of Management Information and Decision Sciences, 25(S3), 1-16.
Abstract
In recent years, electronics sector has been the fastest growing sector in India. The major factors include urbanization, digitalization, emerging technologies like Internet of Things (IoT) and 5G, etc. Unsurprisingly, the amount of data available for this sector has also grown exponentially. Social Media has emerged as the goldmine for data, although the data available is usually unstructured. Thus, analyzing and deciphering meaning out of it becomes tedious. The customer reviews and opinions on the social media platform carry much significance nowadays, both for end users and corporates. These opinions have a prominent influence on the user choices and preferences, while these help the corporates to enhance their decision- making. Twitter is used extensively to get insights on public sentiments since it is a free and open- source of data. The paper presents lexicon- based sentiment analysis of the major competitors in the electronics sector in India. Twitter API has been used to extract the data and R has been used for pre- processing, evaluating and analyzing the tweets, followed by sentiment analysis.
Keywords
Twitter tweets; Data mining; Opinion mining; Machine learning; Deep learning; Lexicon based sentiment analytics.
Introduction
The world’s most treasured asset today is no longer oil, but data (Bhageshpur, 2019; Dixit & Choudhary, 2020; Choudhary & Dixit, 2020). There has been an exponential increase in the size of data in this decade. In 2020, the volume of data has reached to terabytes, petabytes and zetabytes. Seagate UK has predicted that the amount of data generated per day globally by 2025 would be in exabytes (Elgendy & Elragal, 2014; Vuleta, 2021). Experts predict that only a small quantity of data is structured, the rest 85% is unstructured and is mainly sourced from Social Media (Eberendu, 2016). Social Media platforms like Facebook, Twitter, Instagram, etc. contribute to at least 1200 petabytes of data (Vuleta, 2021).
Since the inception, humans have felt the necessity to communicate with their social group and express their views. Due to the advancements in technology, Social Media has become an inseparable part of our lives. On the individual front, it provides an opportunity to connect with family and acquaintances, while on the professional front; it provides opportunity to connect with people having similar interests, profession, job roles and skills. Currently, there are 3.96 billion active users on Social Media. The growth has been led by Asia with 16.98% increase in active users (Dean, 2021).
Till the last decade, people usually conducted surveys and interviews to get insights on public opinion. These techniques are tedious, expensive and time-taking. With the advent of Big Data Analytics, public opinion and emotions can be ascertained with the help of Social Media platforms. Twitter is one of the extensively used micro-blogging site where users can freely express their views, perspective, opinions, sentiments and thoughts on numerous topics in the form of posts, comments, tweets, stories, reviews, etc. (Younis, 2015).
The technique of extracting and elucidating opinions and sentiments from the data is called Sentiment Analysis. This technique assists the organisations to understand public perspective towards their products, services, website (Dixit & Choudhary, 2018), brand, performance, ambience, etc. This helps them in better decision-making for their benefit. For instance, companies like IBM, Twitter and Intel use Sentiment Analysis to discern employee satisfaction and concerns (Brown, 2015). Sentiment Analysis also called as Opinion Mining can be conducted by various approaches like Lexicon based approach, Learning based approach and Hybrid approach (El Alaoui et al., 2018). In this paper, the authors have applied Lexicon based approach via Dictionary Method. This method calculates the sentiment score based on the semantic orientation of words and phrases that occur in a text or a post. A dictionary of positive and negative words is a prerequisite in this method. The authors have collected twitter tweets data till 22nd July 2021 for this work. The user’s text is visualized as a reservoir of words and sentiment value is linked to each word corresponding to the dictionary. A mathematical function like average or sum is applied to predict the overall sentiment score for the text. The results highlight the polarity of the tweets for each of the competitor, along with the overall sentiment score. It has been concluded that Panasonic has the highest number of positive tweets while Bosch has the maximum number of negative tweets. Although the neutral tweets for most companies are higher with respect to their positive and negative tweets.
Literature Review
The researchers attempted to provide insights about Coronavirus outbreak via Machine Learning algorithms. The paper analyzed how people reacted to the pandemic, how much they were aware about the ailment and its symptoms, what preventive measures they were taking, how much they were adhering to the government guidelines, etc. The research concluded that people were aware about symptoms, preventive measures and government policies (Iyer & Kumaresh, 2020).
The paper focused on perceiving public sentiments for Aarogya Setu app on Twitter after its alleged hacking. It was concluded that there was an increase in negative sentiments against the app after alleged hacking (Garg et al., 2020).
The point of study was to analyze tweets about Saudi Universities, posted by Saudi Twitter users. The paper employed 2 models. The first model was based on tweets collection and pre-processing. Latent Dirichlet Allocation was used to discard neutral tweets and for tweets classification, Support-Vector Machine (SVM) was used. The second approach encompassed using various classified models like Naïve Bayes (NB), Stochastic Gradient Descent (SGD), Sequential Minimal Optimization (SMO), K-nearest neighbors Classifier (KNN), Random Forest, Multilayer Perceptrons using Deep-Learning, (MPD), and Sentiment Score Calculation (SSC). It was concluded that SVM model surmounted all the other models presented in the study (Alruily & Shahin, 2020).
The authors proposed to study public sentiments on Twitter for General Elections in India. Twitter API was used for collecting the tweets and R was used for later steps. There was a candidate taken from the two famous political parties. The results obtained coincided with the election results for 2019 (Sharma & Ghose, 2020).
Twitter micro- blogging was applied to comprehend the public perception about the performance of proposed 5G Technology using Machine Learning and Deep Learning algorithm. The results indicated that the Deep Learning tool, i.e., Recurrent Neutral Networks (RNN) showed higher sentiment classification success compared to other algorithms (Seçkin & Kimimci, 2020).
In this paper, Opinion Mining was carried out on Twitter dataset that demonstrated sentiments on Moji ji’s Digital India campaign. The results showed that out of the total collected opinions, 50% were positive, 20% were negative and 30% were neutral (Mishra et al., 2016).
Patil and Gupta presented a study on various approaches in Opinion Mining. There are two main approaches: Machine Learning and Lexicon-based. The Machine Learning approach is further sub-divided as Supervised and Unsupervised, while Lexicon-based approach is sub-divided as Dictionary based and Corpus based. The paper concluded that Machine learning technique (Supervised) performed better than Lexicon-based with respect to accuracy. However, in terms of training time, Lexicon-based approach outperformed Machine Learning approach as the former requires additional training time. Thus, a combined approach can be used for increased accuracy and stability (Patil & Gupta, 2021).
Researchers proposed to carry out Sentiment Analysis on the efforts taken by Saudi General Entertainment Authority (GEA) by analyzing Twitter data. It was inferred that Saudis were happy with GEA’s work. The support rate was higher among females, compared to males (Alkhaldi et al., 2020).
The research emphasized on deducing Airport Service Quality (ASQ) of Heathrow Airport in London by Sentiment Analysis of Twitter data. It was inferred that ground transport and wait time were most quoted aspects. Attributes like Wi-Fi, food and beverages and lounge services were appreciated while attribute like waiting, parking, immigration, staff and passport control can be improved (Martin-Domingo et al., 2019).
The point of study was to develop a sentiment lexicon for the field of kalology in Saudi dialect and to perform lexicon-based Sentiment Analysis using Twitter API for 10 beauty clinics in Riyadh district. Later, the results were evaluated and ranked according to Multi Attribute Utility theory. It was found that the best beauty clinic in Riyadh was Abdelazim Bassam Clinic (Zain et al., 2020).
Methodology
Tools and Techniques
Twitter mining: Data Mining refers to discovering and extracting patterns, trends, relationships and correlations from the large datasets. When data mining is done on Twitter, it is called Twitter Mining. Twitter is the treasure house of data (Sistilli, 2021). With more than 500 million users, it has emerged as one of the principle platforms for users to express their opinion and for companies to scrutinize their brand position via different tools and techniques like Sentiment Analysis (Sarlan et al., 2014; Dixit & Choudhary, 2018).
There are numerous factors that provides twitter an edge over other social media platforms for Data Mining. First, the user’s tweets are publicly available and extractable with the help of APIs. Second, millions of tweets are posted daily, resulting in enormous size of data. Third, the restricted character limit up to 280 characters gives a comparatively homogenous corpus (Rul, 2019).
Still the data available on Twitter is mostly unstructured and noisy. It usually contains punctuation errors, spelling mistakes, emoticons and grammatical errors. Thus, analysing it becomes slightly laborious. To overcome this difficulty, data mining is done with the help of R programming language.
ROAuth package in R is used for authenticating, validating and connecting to Twitter to get access to secured data (Sarkar, 2014). TwitteR package in R allows access to the twitter API and helps in retrieving the tweets (Lee, 2020). These tweets can later use to get understanding of the public sentiments.
Sentiment analysis: Sentiment Analysis, also known as Opinion Mining or Emotional Artificial Intelligence helps to comprehend people’s disposition and sentiments about a topic, occasion, organisation, etc. by identifying, retrieving, examining and analysing their posts, reviews and actions on social media via Natural Language Processing (NLP), text analysis and computational linguistics. The opinion and perspective can be in the form of judgement, disappointment, dissatisfaction, assessment, investigation, recommendation, aggression, desires, etc. The primary goal behind opinion mining is to determine the polarity of the posts, tweets, reviews, etc. and categorise them into emotions like positive, negative or neutral. In addition to polarity, the sentiment analysis model may also be used to study emotions, such as happy, sad, angry etc., or the urgency of a situation or even the intent, such as interested vs not interested. Some of the most popular types of sentiment analysis have been summarized here.
Fine grained sentiment analysis: Sentiment Analysis normally categorizes statements into three categories such positive, negative and neutral. But at times depending on the precision required the categories of polarity may be expanded to further levels such as very positive, positive, neutral, negative and very negative. This extension of polarity levels is called as fine grained sentiment analysis. Such categorization is used in interpreting 5 star ratings.
Emotion detection: This helps in mining opinions and detecting emotions such as happiness, sadness, anger, irritation, frustration etc. Most such systems use lexicons which are lists of words that convey specific emotions such as bad, kill etc. But these words may be conveying positive emotions also such as “This brand is a killer”, meaning that the brand is doing extremely well and may be capturing the market. Hence at times this may lead to erroneous results also.
Aspect based sentiment analytics: In the process of mining the opinions about a brand, the user may be interested in categorizing it into aspects or features being referred to by people in their reviews or comments. For example the camera resolution of this cell phone is not very good. So in this case the aspect based classifier is pointing to the negative opinions regarding the feature camera resolution of the cell phone.
Intent analysis: This involves a deeper understanding of the intent of the consumer to buy. For example if an organization is able to find out the actual intent of the customer that whether he is planning to buy the product or is simply surfing and exploring for any possible purchase in future, the they can decide on their marketing strategies. Accurate determination of the customer’s intent can help the organization in expending their marketing and advertising efforts in a fruitful manner and prevents them from chasing customers who do not intend to buy.
So after studying the types of sentiment analytics, we can see the mathematical formulation of the process of sentiment analytics.
Mathematically, opinion can be expressed as
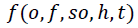
Where,
o = Object
f = Feature of object
so = Polarity of opinion
h = Opinion Holder
t = time of expressing the opinion (Kharde & Sonawane, 2016)
With the advancement in Information Technology, the world has moved towards digital mode. Social Media has become the prime stage where people express their feelings, emotions and views. Due to this, Sentiment Analysis has gained much significance over these years in every field ranging from marketing and sales to customer service and pricing. This technique helps the brands in understanding the customer need, requirement and expectation in a better way and perceiving what makes the customer satisfied or frustrated. This results in targeted decision- making to improve products and services (Drus & Khalid, 2019). Sentiment Analysis has found its application in various fields like politics, apparel industry, sports, transport industry, etc. (Mahtab et al., 2018; Rasool et al., 2019; Saragih & Girsang, 2017; Sharma & Ghose, 2020).
Sentiment Mining can be carried out on 3 levels
Document level sentiment mining: In this level, the whole document is considered as a single entity for analysis and classification as positive, negative or neutral.
Sentence level sentiment mining: In this level, the sentence is considered as a single entity for analysis and classification as positive, negative or neutral.
Aspect level or entity level sentiment mining: In this level, the sentiment classification into positive, negative or neutral is done based on the features or specific target words present in the document, text or sentence (Pradhan et al., 2016).
There are various algorithms that can be implemented for Opinion Mining to determine the emotional tone behind online conversations. These algorithms fall into three categories:
Rule based sentiment analysis approach: This set of algorithms use a dictionary of words which are categorized into labelled sentiments to help determine the sentiments conveyed by the sentence. Sentiment scores combined with additional rules, which are manually crafted, can be used for segregating the sentences to reflect varied meanings or sentiments such as praise, negation, sarcasm etc. Rule based approach uses NLP techniques such as stemming, tokenization, parsing and works with lexicons.
Automatic or machine learning based sentiment analysis approach: In this approach a machine learning model is trained to recognize sentiments based on words and the order in which they appear using a training set that has labelled sentiments. This approach depends to a large extent on the type of algorithm and the quality of the data being used for training the algorithm. This approach is usually modelled in the form of a classification problem with the classifier returning the category of the text. The classification uses any one of the statistical models such as Naïve Bayes, Logistic Regression, SVM (Support Vector Machines), or Neural Networks.
Hybrid approach: This category of algorithms combines rule based and machine learning approaches.
In this paper, the authors have applied Lexicon based approach via Dictionary Method and we will be discussing this method in detail here.
Lexicon based approach: This method calculates the sentiment score based on the semantic orientation of words and phrases that occur in a text or a post. A dictionary of positive and negative words is a prerequisite in this method. The users may create the dictionary or choose to use an existing one, WorldNet is a popular dictionary used by most researchers. The user’s text is visualized as a reservoir of words and sentiment value is linked to each word corresponding to the dictionary. A mathematical function like average or sum is applied to predict the overall sentiment score for the text. This technique uses the adjectives and adverbs to discover the semantic orientation of the text. Sentiment scores are given to combinations of adjectives and adverbs and this score is used for finding the sentiment orientation, which can further be converted to a single score for the complete document. Lexicon based approach can be further categorized into the following two types:
a) Dictionary Based Approach: Here a dictionary is created by initially picking some words from the document, then refining and expanding it by picking synonyms and antonyms from some online dictionary such as WordNet. This expansion continues till there are no new words to be added. The dictionary so created can be refined by manual inspection also.
b) Corpus Based Approach: This approach helps find the sentiment orientation of context specific words. This may be done via statistical method or semantic method. In the statistical method, the words that show erratic behavior in positive text are considered as positive polarity. While words that show negative intent in negative text are considered as negative polarity. If the frequency of both negative and positive words is equal then it is neutral polarity. In the semantic approach sentiment scores are assigned to words and to the words which are semantically close to them, such as the synonyms and antonyms of those words.
In this paper lexicon based approach with dictionary method has been used. The entire process has been implemented in R and the following R packages have been used for Sentiment Analysis:
• twitteR: This package helps to fetch the tweets with the help of Twitter API.
• ROAuth: OAuth is a token that will help to authenticate R and to provide interface to R for accessing data.
• plyr: This package delivers control over the data by manipulating the data and breaking the data into manageable pieces.
• stringr: This package is primarily used for string processing and helps to make the working with strings easy.
• ggplot2: This package is The Grammar of Graphic in which the results are plotted based on the data provided.
Methods
The aim of this research paper is based on analyzing the public sentiments and opinions about the 6 major competitors in the Electronics Sector. The dataset used is primary in nature. The steps of the process are as below:
First step: The first step focused on understanding, exploring and retrieving the data. In order to extract specific tweets for each competitor, query was generated using the official Twitter handle through Twitter API. A total of 780 tweets have been extracted for each competitor. The tweets have been collected till 6 December 2021. The companies like Sony; Samsung; LG Electronics; Philips; Panasonic; and Bosch have been considered.
Second step: In the second step, the already developed and freely accessible positive and negative lexicon were taken from an online source (Hu & Liu, 2004; Liu et al., 2005). Since the data has been extricated from an online platform, it contained noise and errors, thus, the need of the third step.
Third step: The third step involved pre- processing and cleaning of the data using R. The data was cleaned to remove punctuation, control characters and digits. The data was then converted from sentence to word level.
Fourth step: In the fourth step, the processed dataset was compared with the positive and negative lexicons to find the number of positive, negative and neutral sentiments. As the result, total sentiment score of each tweet for each competitor was calculated and visualized.
Fifth step: In the fifth step, a polarity plot was created to visualize the positive, negative and neutral sentiments of each competitor in a better way. To compare the sentiments of each competitor, pie- chart was created for better analysis.
Results and Discussion
The words and phrases that contain a semantic orientation is called lexicon and this approach has been used to perform Sentiment Analysis in this paper. The paper focuses on determining the polarity of the tweets and assigning them sentiment score. Hu and Liu (2004); and Liu et al. (2005) created an opinion lexicon, for general purpose that groups commonly prevailing English words into positive and negative words. There is a total of two thousand and six positive words and four thousand seven hundred and eighty- three negative words in the opinion lexicon. The positive and negative lexicon has been illustrated in Figure 1.

Figure 1: Word Cloud Of Dictionary Lexicon: (A) Positive Lexicon, (B) Negative Lexicon.
The positive and negative opinion lexicon is matched with the processed tweets to determine the polarity of each tweet of the six major competitors in the electronics sector. A total of 780 tweets have been extracted till 6 December 2021 to determine the public sentiment for each of the company. Table 1 portrays the number of positive, negative and neutral tweets for each company. The same has been depicted in the Figures 2-7.
| Table 1 Tweet Classification |
||||
|---|---|---|---|---|
| Company | Positive Tweets | Negative Tweets | Neutral Tweets | Total Tweets |
| Sony | 121 | 89 | 570 | 780 |
| Samsung | 225 | 117 | 438 | 780 |
| LG Electronics | 147 | 160 | 473 | 780 |
| Philips | 141 | 289 | 350 | 780 |
| Panasonic | 233 | 111 | 436 | 780 |
| Bosch | 298 | 122 | 360 | 780 |

Figure 2:Tweet Classification For Samsung.

Figure 3:Tweet Classification For Sony.

Figure 4:Tweet Classification For Philips.

Figure 5:Tweet Classification For Lg Electronics.

Figure 6:Tweet Classification For Bosch.

Figure 7:Tweet Classification For Panasonic.
The final sentiment score of each tweet is calculated by subtracting the total positive words from the total negative words in a tweet.
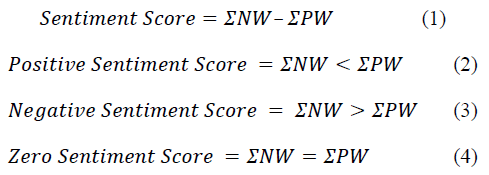
A sentiment score of zero signifies the opinion words are absent in the tweets while the positive and negative score indicates the positive and negative polarity of the tweets respectively. Table 2 depicts the number of tweets with different sentiment scores for each competitor. Figures 8-13 illustrate the same in a graphical form.
| Table 2 Tweet Sentiment Score |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Company | -6 | -5 | -4 | -3 | -2 | -1 | 0 | 1 | 2 | 3 |
| Sony | 0 | 0 | 0 | 3 | 8 | 78 | 570 | 90 | 27 | 3 |
| Samsung | 0 | 1 | 0 | 6 | 21 | 89 | 438 | 171 | 42 | 8 |
| LG Electronics | 1 | 0 | 2 | 32 | 29 | 96 | 473 | 106 | 33 | 5 |
| Philips | 0 | 0 | 1 | 5 | 13 | 270 | 350 | 100 | 34 | 4 |
| Panasonic | 0 | 0 | 0 | 0 | 14 | 97 | 436 | 183 | 50 | 0 |
| Bosch | 0 | 0 | 0 | 4 | 59 | 59 | 360 | 244 | 48 | 5 |

Figure 8:Sentiment Score For Samsung.

Figure 9:Sentiment Score For Sony.

Figure 10:Sentiment Score For Philips.

Figure 11:Sentiment Score For Lg Electronics.

Figure 12:Sentiment Score For Panasonic.

Figure 13:Sentiment Score For Bosch.

Figure 14:Comparative Analysis Of Positive Tweets Among Different Competitors.

Figure 15:Comparative Analysis Of Negative Tweets Among Different Competitors.

Figure 16:Comparative Analysis Of Neutral Tweets Among Different Competitors.
It can be concluded that Bosch has the highest number of positive tweets while Philips has the maximum number of negative tweets. Although the neutral tweets for most companies are higher with respect to their positive and negative tweets.
Conclusion
The study presents sentiment analysis of the major competitors in the Electronics sector in India. It aims to integrate text mining with sentiment analysis which are generally considered as distinct topics. The research begun with data collection via Twitter API, followed by its processing and comparison with the sentiment lexicon. The tweets were then classified into positive, negative and neutral tweets and the final sentiment score was calculated. The dataset used is primary in nature and a systematic approach was used.
The results depicted the public sentiments for different competitors along with their sentiment scores. It was observed that Bosch has the highest number of positive tweets while Panasonic has the maximum number of negative tweets. The scope of this study is limited to the textual data collected from Twitter. Since the data has been extracted from an online platform, it was noisy which added to the complexity. This study can assist these companies in understanding how they are faring in the eyes of their customers and aid them in getting insights of how they can stand out from their competitors. It will also impact the decision- making and marketing strategies of the companies with focus on improving their products and services. It will also enable them to understand their customers in a better way.
In the future, a manual lexicon can be created based on the collected data for higher accuracy in prediction. The companies could be ranked based on the public sentiment scores with the help of novel techniques like Multi-attribute Utility Theory. Another future recommendation is to assign polarity to the emoticons used in the tweets.
References
Alkhaldi, S., Alzuabi, S., Alqahtani, R., Alshammari, A., Alyousif, F., Alboaneen, D. A., & Almelihi, M. (2020, March). Twitter Sentiment Analysis on Activities of Saudi General Entertainment Authority. In2020 3rd International Conference on Computer Applications & Information Security (ICCAIS)(pp. 1-5). IEEE.
Indexed at, Google Scholar, Cross Ref
Alruily, M., & Shahin, O.R. (2020). Sentiment Analysis of Twitter Data for Saudi Universities. International Journal of Machine Learning and Computing, 10(1), 18-24.
Indexed at, Google Scholar, Cross Ref
Bhageshpur, K. (2019). Data Is The New Oil -- And That's A Good Thing. Forbes.
Brown, J. (2015). Companies using sentiment-analysis software to understand employee concerns. Ciodive.
Choudhary, S.L., & Dixit, R.S. (2020). The Convergence of Internet of Things and Big Data. In: Sharma, L. (Ed.). (2020). Towards Smart World: Homes to Cities Using Internet of Things (1st ed.). Chapman and Hall/CRC.
Indexed at, Google Scholar, Cross Ref
Dean, B. (2021). Social Network Usage & Growth Statistics: How Many People Use Social Media in 2021?. Backlinko.
Dixit, R.S, & Choudhary, S. (2018). Website Usability Evaluation through Sentiment Analysis of the User Population of the IRCTC Website. International Journal of Applied Engineering Research, 13(21), 15317-15328.
Dixit, R. S., & Choudhary, S. (2020). Internet of Things Enabled by Artificial Intelligence. In: Sharma, L. (Ed.). (2020). Towards Smart World: Homes to Cities Using Internet of Things (1st ed.). Chapman and Hall/CRC.
Indexed at, Google Scholar, Cross Ref
Drus, Z., & Khalid, H. (2019). Sentiment Analysis in Social Media and Its Application: Systematic Literature Review. Procedia Computer Science, 161, 707-714.
Indexed at, Google Scholar, Cross Ref
Eberendu, A. C. (2016). Unstructured Data: an overview of the data of Big Data.International Journal of Computer Trends and Technology,38(1), 46-50.
El Alaoui, I., Gahi, Y., Messoussi, R., Chaabi, Y., Todoskoff, A., & Kobi, A. (2018). A novel adaptable approach for sentiment analysis on big social data.Journal of Big Data,5(1), 1-18.
Indexed at, Google Scholar, Cross Ref
Elgendy, N., & Elragal, A. (2014, July). Big data analytics: a literature review paper. InIndustrial conference on data mining(pp. 214-227). Springer, cham.
Indexed at, Google Scholar, Cross Ref
Garg, I., Kiran, D., & Sharma, I. (2020, October). Sentimental Analysis of “Aarogya Setu”. In2020 International Conference on Smart Innovations in Design, Environment, Management, Planning and Computing (ICSIDEMPC)(pp. 263-267). IEEE.
Indexed at, Google Scholar, Cross Ref
Hu, M., & Liu, B. (2004, August). Mining and summarizing customer reviews. InProceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining(pp. 168-177).
Indexed at, Google Scholar, Cross Ref
Iyer, D. K., & Kumaresh, D.S. (2020). Twitter Sentiment Analysis On Coronavirus Outbreak Using Machine Learning Algorithms.European Journal of Molecular & Clinical Medicine,7(3), 2663-2676.
Kharde, V., & Sonawane, P. (2016). Sentiment analysis of twitter data: a survey of techniques.International Journal of Computer Applications, 139(11), 5-15.
Indexed at, Google Scholar, Cross Ref
Lee, J. (2020). Pulling Tweets into R. Towards Data Science.
Liu, B., Hu, M., & Cheng, J. (2005, May). Opinion observer: analyzing and comparing opinions on the web. InProceedings of the 14th international conference on World Wide Web(pp. 342-351).
Indexed at, Google Scholar, Cross Ref
Mahtab, S. A., Islam, N., & Rahaman, M. M. (2018, September). Sentiment analysis on bangladesh cricket with support vector machine. In2018 International Conference on Bangla Speech and Language Processing (ICBSLP)(pp. 1-4). IEEE.
Indexed at, Google Scholar, Cross Ref
Martin-Domingo, L., Martín, J. C., & Mandsberg, G. (2019). Social media as a resource for sentiment analysis of Airport Service Quality (ASQ).Journal of Air Transport Management,78, 106-115.
Indexed at, Google Scholar, Cross Ref
Mishra, P., Rajnish, R., & Kumar, P. (2016). Sentiment analysis of Twitter data: Case study on digital India. In2016 International Conference on Information Technology (InCITe)-The Next Generation IT Summit on the Theme-Internet of Things: Connect your Worlds(pp. 148-153). IEEE.
Indexed at, Google Scholar, Cross Ref
Patil, A., & Gupta, S. (2021). A Review on Sentiment Analysis Approaches.
Pradhan, V.M., Vala, J., & Balani, P. (2016). A survey on sentiment analysis algorithms for opinion mining.International Journal of Computer Applications,133(9), 7-11.
Indexed at, Google Scholar, Cross Ref
Rasool, A., Tao, R., Marjan, K., & Naveed, T. (2019, March). Twitter sentiment analysis: A case study for apparel brands. InJournal of Physics: Conference Series(Vol. 1176, No. 2, p. 022015). IOP Publishing.
Indexed at, Google Scholar, Cross Ref
Rul, C.V. (2019). A Guide to Mining and Analysing Tweets with R. Towards Data Science.
Saragih, M.H., & Girsang, A.S. (2017, November). Sentiment analysis of customer engagement on social media in transport online. In2017 International Conference on Sustainable Information Engineering and Technology (SIET)(pp. 24-29). IEEE.
Indexed at, Google Scholar, Cross Ref
Sarkar, D. (2014). Twitter Authentication for extracting tweets. RPubs by RStudio.
Sarlan, A., Nadam, C., & Basri, S. (2014). Twitter sentiment analysis.Proceedings of the 6th International Conference on Information Technology and Multimedia, 2014 (pp. 212-216). IEEE.
Seçkin, T., & Kilimci, Z.H. (2020, October). The Evaluation of 5G technology from Sentiment Analysis Perspective in Twitter. In2020 Innovations in Intelligent Systems and Applications Conference (ASYU)(pp. 1-6). IEEE.
Indexed at, Google Scholar, Cross Ref
Sharma, A., & Ghose, U. (2020). Sentimental analysis of twitter data with respect to general elections in india.Procedia Computer Science,173, 325-334.
Indexed at, Google Scholar, Cross Ref
Sistilli, A. (2021). Twitter Data Mining: A Guide to Big Data Analytics Using Python. Developers.
Vuleta, B. (2021). How Much Data Is Created Every Day? [27 Staggering Stats]. SeedScientific.
Younis, E. M. (2015). Sentiment analysis and text mining for social media microblogs using open source tools: an empirical study.International Journal of Computer Applications,112(5).
Zain Z.M. Alhajji, A.A., Alotaibi, N.S., Almutairi, N.B., Aldawas, A.D., Almazrua, M.M., & Alhammad, A.M. (2020). Ranking Beauty Clinics in Riyadh using Lexicon Based Sentiment Analysis and Multiattribute-Utility Theory. International Journal of Advanced Computer Science and Applications, 11(10), 66-75.
Indexed at, Google Scholar, Cross Ref
Received: 05-Jan-2022, Manuscript No. jmids-22-10762; Editor assigned: 06-Jan-2022, PreQC No. jmids-22-10762(PQ); Reviewed: 14-Jan-2022, QC No. jmids-22-10762; Revised: 25-Jan-2022, Manuscript No. jmids-22-10762(R); Published: 29-Jan-2022